
grep your way to a lazier future

Entry posted by bubblehash
1541 views
The types of techniques I use in this post can make your life easier in lots of ways. I use grep and sed all the time for things like hunting down and changing ET config vars across my install. The awk usage, in particular, is kinda cool because it shows a simple way to save some state between lines of text in a string of Linux commands. A real world example of grep saving the day is running my ET client with full debug logging enabled then using grep on the output to look for an issue with one of the values in my autoexec. If that didn't work I was about to reset my install, again. Which would've sucked, because I didn't backup my etkey until the next day.
-----------------------------------------------------
My team at work recently got handed an extremely outdated web app written in Node 6 and Angular 2. For how quickly UI frameworks have advanced in recent years, simply calling this code outdated would be an injustice. We gave the frontend to a specialist team and decided to rewrite the API layer with ASP.NET Core 3.0 because we're not masochistic psychopaths. I would've taken on the frontend work if not for the fact that I'm a complete assclown when it comes to UI dev. I can do lots of cool stuff on the backend, but it's always fun to watch good UI people do their thing. I worked with a woman from Facebook for a while who could make magic happen. I'm convinced she was a wizard.
Before we could move forward with our work and start designing a new API, we needed 3 critical pieces of info:
-
Current API footprint
- Any web app that's been around longer than 7 minutes probably has deprecated APIs that just sit there...unused and unloved.
-
Backend data models
- We don't want to copy bad decisions from the past, but we need to know the overall shape of the data to make it better. We also need to be able to write a mapping layer or tool for data migration.
-
Frontend data models
- Being part of the big tech grind wheel has taught me that new backends always hit version 1 faster than their frontend counterparts. We just have to not break stuff while they're stuck trying to keep the UX designers and product folks happy (those poor bastards). Being able to plug into the legacy system lets us release our backend behind the old frontend and achieve a much smoother release.
We left the task open for a junior dev to knock out, but it sat long enough that I started getting frustrated. I found myself in between tasks so I decided to just get it done. My goal was to prove that the task could be accomplished with a few key presses, and the Linux command line is my favorite programming language, so I was pretty sure I could pull it off. My career moved away from Linux ~4 years ago so it took some head scratching to remember all the grep/sed regex difference, but, in the end, I had a listing of our legacy APIs and data models. One of the junior devs that I was frustrated with was actually the one that asked me to write up a walkthrough of the commands which totally made my day. I love you guys, but getting paid to break down the commands is the main reason I have this content to share ![]()
It had literally never occurred to him that this kind of approach was a possibility. It's amazing how different the mindsets can be between developers based on their career paths (also exactly why working on a good team can help you grow so much).

Since I like getting paid, I had to find another codebase where we could go spelunking. It took a little bit of hunting through github because the UI tech in question is over 4 years old, but I managed to find one that used the same API definition style in a 4 year old commit. I'm using git bash for Windows in the screenshots below because I don't have the Linux subsystem enabled on this laptop, but it works just as well for most command line hackery.
Git for Windows: https://gitforwindows.org/
Codebase: https://github.com/habukira/Azure-azure-iot-device-management/tree/61e8646203847e726bf9f5cbd1945a5e0563cd0a (This looks like a fork someone made of a Microsoft project)
I apologize in advance for the blinding white text and overall color scheme. I had to make it brighter for screenshots. Just know that I suffered with you.
The first step is to clone the repository and rewind the clock back 4 years.
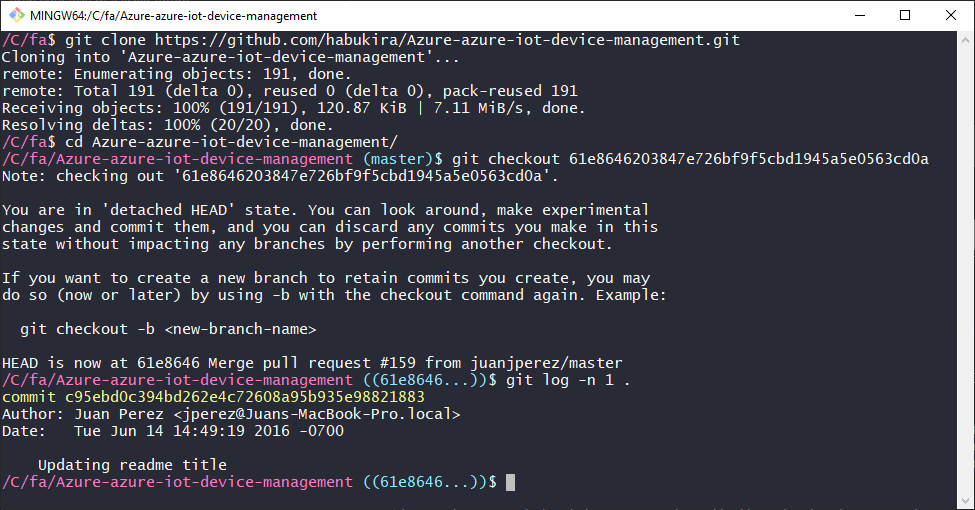
git clone https://github.com/habukira/Azure-azure-iot-device-management.git cd Azure-azure-iot-device-management/ git checkout 61e8646203847e726bf9f5cbd1945a5e0563cd0a git log -n 1 .
Now we're ready to make our lives easier by thinking really, really hard. I refuse to spend an hour clicking through files to copy and paste stuff when I can spend that time making the computer do it for me. Since I just wanted to find text and change it around a little, I opted for grep, sed, and awk. At a (very) high level, grep is used to look for string/regex matches in files, and sed is for manipulating text with regular expressions. Then there's awk which is a brilliantly horrible monster that can do so much that you only ever learn enough to do your current task. It's perfect ![]()
The API code looks like the following:
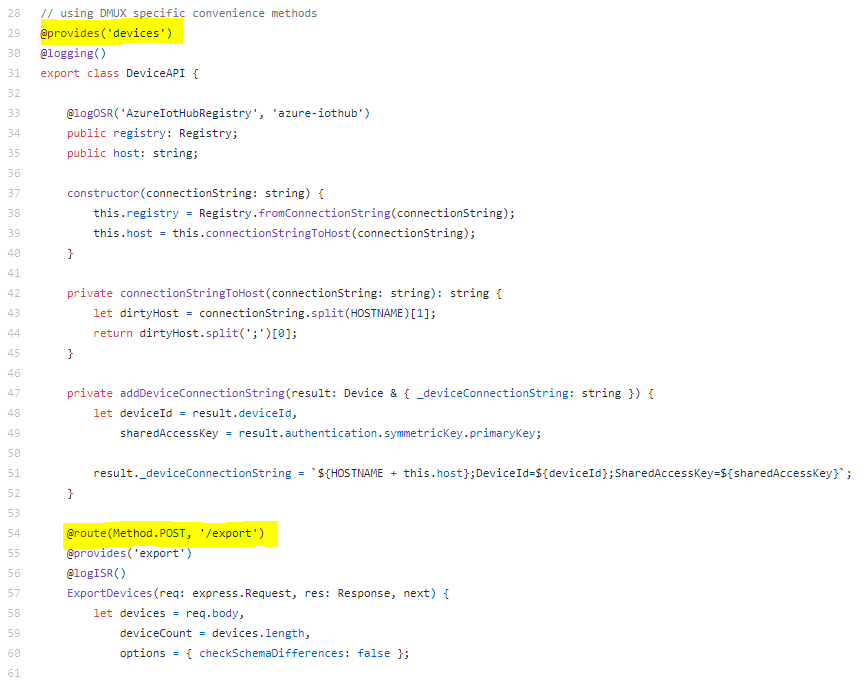
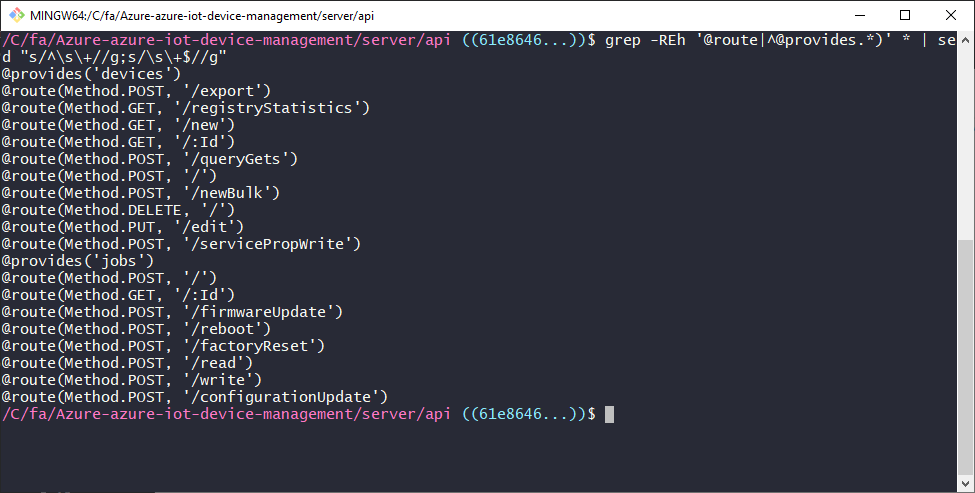
Like I said before, I have no real knowledge of the code I'm looking at, but it's pretty easy to pick out the only details I care about. My goal here is to build a list of the URLs we need to support along with their supported HTTP verbs. It looks like "@provides" gives us the root of the URL path (the portion after the domain name) while "@route" gives us the rest of the path and the verb. We need to take some care because the "@provides" annotation shows up in multiple contexts (top of file and at the function level), but otherwise this seems doable.
Here it is in all it's glory before we walk through it:
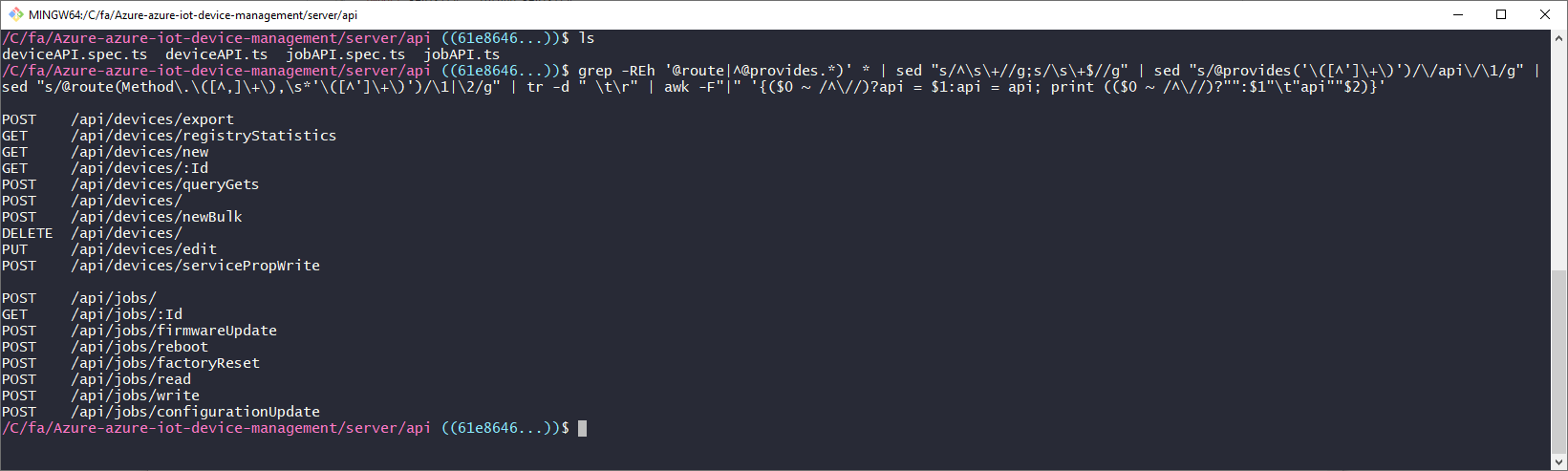
Here are the commands broken out to make them easy less difficult to read:
grep -REh '@route|^@provides.*)' * | sed "s/^\s\+//g;s/\s\+$//g" | sed "s/@provides('\([^']\+\)')/\/api\/\1/g" | sed "s/@route(Method\.\([^,]\+\),\s*'\([^']\+\)')/\1|\2/g" | tr -d " \t\r" | awk -F"|" '{($0 ~ /^\//)?api = $1:api = api; print (($0 ~ /^\//)?"":$1"\t"api""$2)}'
grep -REh '@route|^@provides.*)' *
|
sed "s/^\s\+//g;s/\s\+$//g"
|
sed "s/@provides('\([^']\+\)')/\/api\/\1/g"
|
sed "s/@route(Method\.\([^,]\+\),\s*'\([^']\+\)')/\1|\2/g"
|
tr -d " \t\r"
|
awk -F"|" '{($0 ~ /^\//)?api = $1:api = api; print (($0 ~ /^\//)?"":$1"\t"api""$2)}'
For anyone that looks at that and recoils in horror at the regex, I used to be the same way. Then I found vim and realized regex makes you a superhero on the command line. Pro tip for learning: just search for the specific thing you're trying to do and look at it enough to understand the patterns.
1. grep -REh '@route|^@provides.*)' *
-
-R
- Recursively search this directory and all subdirectories.
-
-E
- Use extended regex parser for the pattern you pass to grep. This isn't strictly required here, but if you don't use it, you're stuck escaping all of your regex which can get kinda hard with grep.
-
-h
- Don't include the filename of the match in the output.
-
'@route|^@provides.*)'
-
'
- Start regular expression match pattern.
-
@route
- Find any lines that have "@route" in them.
-
|
- The "or" syntax for regular expressions.
-
^@provides.*)
- Find lines that start with @provides (the ^ character means start of line) and have zero or more of any character (the . is the wildcard and * means zero or more) before finally ending with a close paren.
-
'
- End pattern.
-
'
-
*
- Search all files
Search all files in current directory and subdirectories for lines that contain either "@route", or lines that start with "@provides" with a close parenthesis somewhere after on the same line. The close paren is there because the framework also uses "@provides" for unrelated things but with braces/brackets instead. The output will contain the full matching lines without filenames.
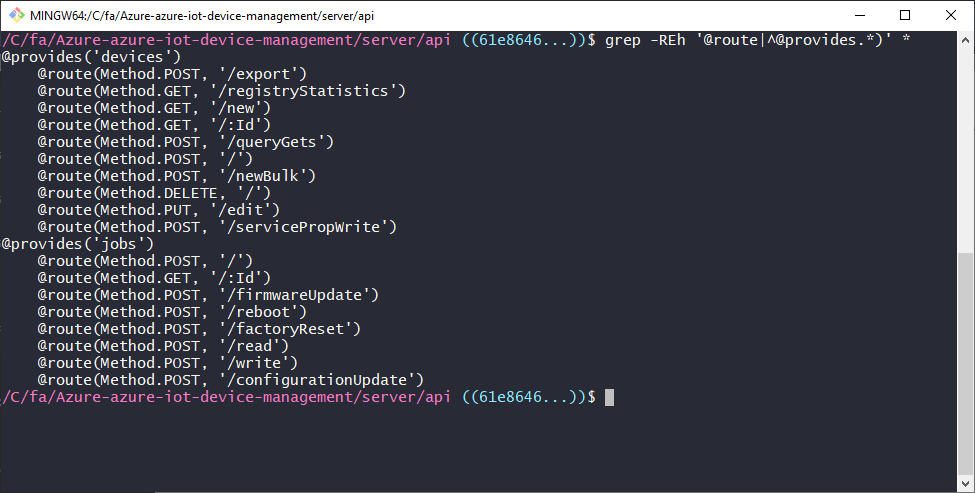
I honestly could've stopped here for the API portion, but I was determined to end up with a list of URLs and verbs in a "nice" looking format. Most sysadmins/programmers out there have burned through irresponsible amounts of time getting the output to match what they had in their brain, and I am no exception.
2. sed "s/^\s\+//g;s/\s\+$//g"
Remove all leading and trailing spaces from the text. This might look a little weird because I'm making use of sed's ability to put multiple expressions in a single call. There are very important differences between calling sed multiple times and passing in multiple expressions, but they don't matter at all in this use-case. This was more of a shorthand way to group my "get rid of spaces" operations. Side note, you'll notice all the escaped characters below. That's because I never bother to use sed's extended regex parser like I do with grep. I learned sed before grep and the escape syntax got stuck in my brain.
-
s/^\s\+//g
-
s
- Tell sed we want to do text substitution.
-
/
- Begin the "look for this text" part of the regular expression.
-
^
- Only find matches that start at the beginning of the line.
- ^ translates to "the start of each line".
-
\s\+
- Match one or more spaces.
- \s is used to match all whitespace characters.
- \+ means only match on one or more of the preceding character.
-
/
- End the "look for" pattern and start the "replace with this text" part of the regular expression.
-
/
- End the "replace with" pattern. There's nothing between the last set of "//" in this example because we want to remove the text we match instead of replace it with something else.
-
g
- Do substitution on all matches found in the input.
-
s
-
s/\s\+$//g
-
$
- This is the only difference from the previous regular expression. This time we want to get rid of one or more spaces at the end of a line.
- $ translates to "the end of the line" which can be either "\n" or "\r\n" depending on your operating system.
-
$
Here's a pretty simple walkthrough of the basic (what I used above) and extended regex parsers available in sed for anyone curious: https://www.gnu.org/software/sed/manual/sed.html#BRE-vs-ERE
3. sed "s/@provides('\([^']\+\)')/\/api\/\1/g"
We start getting into more advanced concepts with this command because we're using "capture groups" to grab part of the "@provides" line and use it in our replacement text.
-
Match pattern
-
@provides('\([^']\+\)')
-
@provides('
- Our matching strings will start with the literal text @provides('.
-
\([^']\+\)
- Here we set up the "capture group" we'll use to save text to use in our replacement. We want to capture all of the text between the single quotes on the "@provides" lines of our input without including the actual quote characters.
-
\(
- Start capturing text.
-
[^']\+
- This is the "only match characters that are/aren't included between the square braces" syntax. We use \+ because we only want matches with one or more characters.
- ^ means "find all the characters that aren't between these braces" when used for character blocks.
- You'll see this pattern all of the time for cases where you want to match on text until a specific character.
-
\)
- Stop capturing text.
-
')
- Our matching strings will end with the literal text ').
-
@provides('
-
@provides('\([^']\+\)')
-
Replacement pattern
-
\/api\/\1
- Replace the "@provides" text with "/api/whatever-was-between-single-quotes". We're trying to turn the output into "real" URL paths, and I happen to know this framework injects "/api/" at the start of every API.
-
\/api\/
- This will translate to the literal text /api/ in the output.
- Forward slash is used for sed's expression syntax, so we have to escape them in our output to make sure sed doesn't get confused.
-
\1
- This tells sed that we want it to inject the text we captured in the match pattern. You can have lots of groups (nested even), and you reference them by backslash and the 1-based index of the groups as they appear in the match pattern. Since we only have one group, we use \1 to get the matching text.
-
\/api\/\1
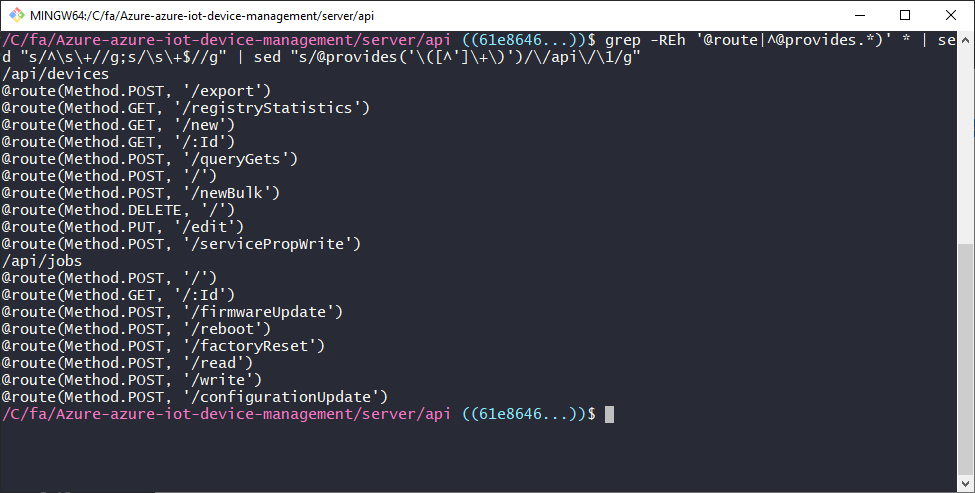
Our top-level URLs are in our output now, but we still need to get the rest of the path and the verb from the "@route" lines.
4. sed "s/@route(Method\.\([^,]\+\),\s*'\([^']\+\)')/\1|\2/g"
There aren't any new concepts here compared to step 3, but it looks more complicated because I'm using 2 capture groups. I want the HTTP verb that comes between "Method." and the comma, and I also want the URL path that comes between the single quotes. Once I have those pieces, I need to output them in a way that makes it really easy to split later.
-
Match pattern
-
@route(Method\.\([^,]\+\),\s*'\([^']\+\)')
-
@route(Method\.
- Our matching strings will start with the literal text @route(Method. so we need to escape the period because otherwise it gets used as the "match literally anything" wildcard character.
-
\([^,]\+\)
- \( [^,]\+ \)
- The first capture group will get all all of the characters until we hit a comma.
-
,\s*'
- There will be a comma, zero or more whitespace characters, and a single quote between the 2 groups of text we want to capture.
- * means match on zero or more characters. You see it a lot with \s because it's an easy way to ignore any whitespace differences in format of the input.
-
\([^']\+\)
- \( [^']\+ \)
- The second capture group will get all of the characters until we hit a single quote.
-
')
- Our matching strings will end with the literal text ').
-
@route(Method\.
-
@route(Method\.\([^,]\+\),\s*'\([^']\+\)')
-
Replacement pattern
-
\1|\2
- We want to output the HTTP verb we captured in our first group and the piece of the URL path we got in our second group. Pipe characters end up being really easy to work with if you're not using the extended regex parser for sed, so I always use it for "need to split later" scenarios.
- Our output will be "<verb><pipe character><path>".
-
\1|\2
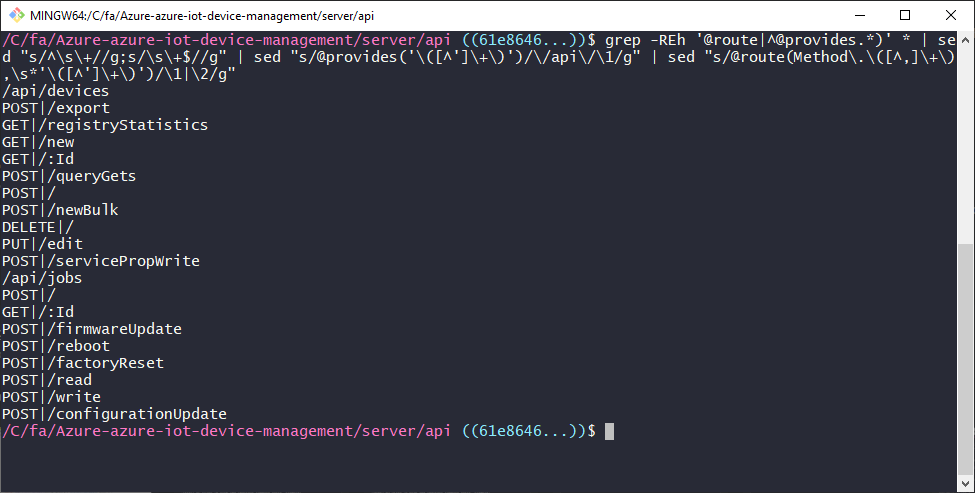
5. tr -d " \t\r"
The tr command is used to translate text. It's a quick and easy tool for when you need to delete or replace specific characters in your input but don't need full pattern matching.
-
-d
- This is the delete flag. It tells tr that we want to delete any occurrences of the characters found between the quotes that follow.
-
" \t\r"
- This command works on characters, not strings, so this input tells tr we want to find the space, tab, and return characters. You'll see stuff like this a lot when dealing with Windows (\r\n) versus Unix (\n only) line endings.
The input that feeds into our last step will be free of all spaces, tabs, and return characters to make sure we don't have to handle any weird edge cases. There's no screenshot for this step because it doesn't have any visible impact with this codebase.
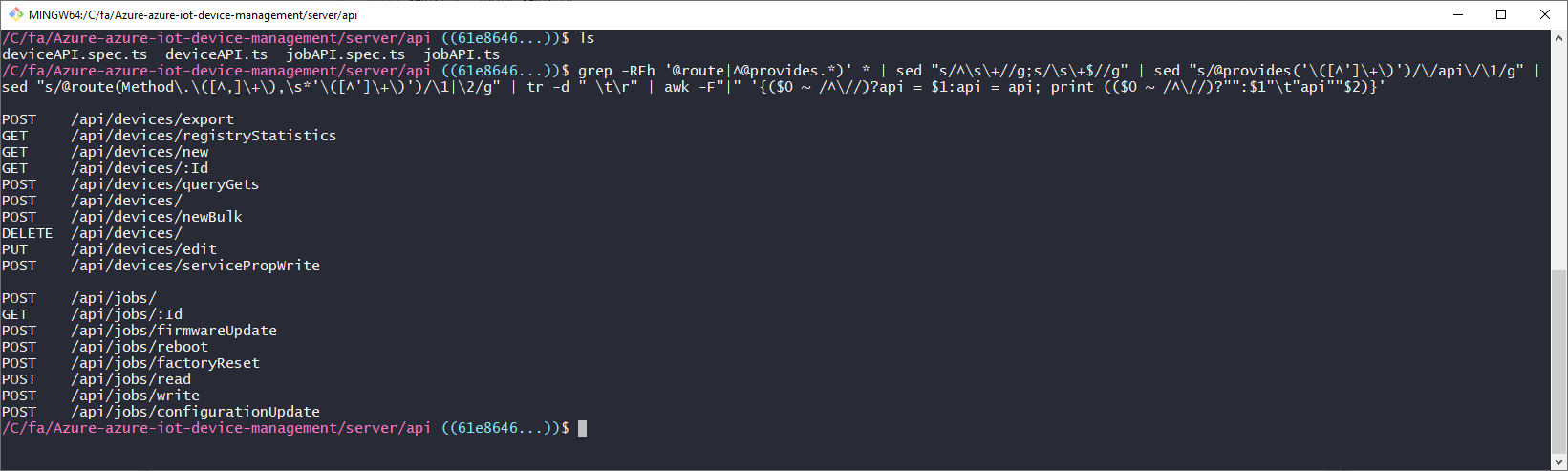
6. awk -F"|" '{($0 ~ /^\//)?api = $1:api = api; print (($0 ~ /^\//)?"":$1"\t"api""$2)}'
I don't know a lot of awk, and I got to learn a little bit more to put this together. The sysadmins that can write full-blown awk scripts are magical beings that should cherished...left to their own devices and isolated from the youth that always pisses them off, but cherished ![]()
This is the command that takes our "root path on top line followed by supported APIs on next lines" input and turns it into "full URLs with their verbs on each line" output.
-
-F"|"
- Input that gets passed in to awk gets treated as groups of text much like our capture groups above. This tells awk to create a new group every time it sees a pipe character on a line of input.
- The important things to know about the awk groups are that you reference them with $ instead of backslash, and the "$0" group is always the full line of input. Even if there aren't any pipe characters, $0 will still have the line of input.
- This won't have any impact on the "api" lines of text, but the "verb/path" lines will end up with the HTTP verb in $1 and the URL path in $2 after splitting on the pipe character.
-
'{($0 ~ /^\//)?api = $1:api = api; print (($0 ~ /^\//)?"":$1"\t"api""$2)}'
- Like sed, awk lets you use semicolon to break up multiple commands in a single call. Unlike sed, though, awk lets you do this in a "programming language" style where you can have logic and other programming constructs.
-
'{
- Start of the command sequence we want to execute.
-
($0 ~ /^\//)?api = $1:api = api
- This is the "ternary operation" syntax for awk. That's a fancy way of saying "if/else statement in a really compact and hard to read format". I try to avoid them when possible, but this was my only option without dropping down into a full awk script which would have violated my "string of commands on the command line" goal. One very important callout is that awk will always parse the "if true" and "if false" portions of the statement so they both need to exist and both must be the same type of operation. For example, you couldn't have it set a variable if true and output some text if false.
-
($0 ~ /^\//)
- The "if" statement piece of the ternary operation.
- This is awk syntax for "does this whole line of input ($0) match the pattern 'starts with forward slash'".
-
?
- End the logic and begin the "do this if true" piece.
-
api = $1
- When our input lines starts with a forward slash, we want to save the text to a variable named "api" for later use.
-
:
- End the "if true" piece and start the "do this if false" part.
-
api = api
- This was a hacky way of getting awk to ignore the lines of text that didn't start with "/api" by telling it to just set the api variable to its current value.
-
;
- End this command and start the next one. The end result of this command is that we'll have a variable named "api" that will contain the text of the "/api/..." lines.
-
print (($0 ~ /^\//)?"":$1"\t"api""$2)
- This is the part that actually builds the output the way we want it.
- The print function does just that. Output text to standard out. It is a function, though, so the text to output is enclosed in parentheses.
-
($0 ~ /^\//)?"":$1"\t"api""$2
- Another ternary operation with the exact same "if statement" as our last command.
-
($0 ~ /^\//)
- Does this input line start with a forward slash?
-
""
- If it does, output a blank string. This is a nice way of getting a line break between the different API files.
-
$1"\t"api""$2
- This combines everything into nice looking output. Side note, awk is weird when it comes to string concatenation. You just kind of put stuff next to each other and make sure literal text is enclosed in quotes.
- $1 gets replaced by the HTTP verb before the pipe character.
- "\t" tells awk to inject the literal text of the tab character.
- api gets replaced with the text we had stored in the "api" variable.
- "" tells awk to use a blank string to concatenate the next part of the string. This was a hacky way to prevent spaces between the parts of the output string as awk is wont to do.
- $2 gets replaced by the URL path after the pipe character.
-
'}
- End of the command sequence.
Putting it all together gives us our nice looking API definition:
Building the data model files is drastically easier in comparison. We just have to concatenate all of the files in a directory together and do some whitespace cleanup to make things pretty. The codebase we're using here doesn't use exactly the same style of data model definition as what I'm dealing with at work, so I'll just share the commands I used.
for f in ./*.ts; do c=`cat $f | tr -d $'\r'`; content=`echo -e "\n$c\n"`; echo "$content" | grep -vE '^import|^\s*\/' | grep -v "^export {[^}]\+} from [^;]\+;$" | sed 's/^\s\+$//g' | sed 'N;/^\n$/D;P;D;' >> /C/fa/frontend.datamodels.ts; done
for f in ./*.ts
do
c=`cat $f | tr -d $'\r'`
content=`echo -e "\n$c\n"`
echo "$content"
|
grep -vE '^import|^\s*\/'
|
grep -v "^export {[^}]\+} from [^;]\+;$"
|
sed 's/^\s\+$//g'
|
sed 'N;/^\n$/D;P;D;'
>> /C/fa/frontend.datamodels.ts
done
The dude on my team only really cared about how I built the API output, so I'm just giving a high level overview of this loop used for data models.
- Loop through every TypeScript file.
- Save the content of each file to a variable after stripping out all return characters.
-
Create a variable that contains the file content from step 2 sandwiched between newline characters.
- Just another "might as well have it look nice" thing.
-
Print that variable content filter the output.
- Strip out import statements and any lines that have slashes (comments, etc.). We just want the raw class structures and instance variable declarations.
- Strip out the export statements that node uses.
- Replace lines that contain only whitespace with blank lines.
-
Do some fancy sed stuff I found online to make a decent effort at collapsing a series of blank lines into a single one. It worked well enough to move on with my life
") It's abusing sed to keep pulling in the next line of input and re-running the pattern deletion match a few times.
It's abusing sed to keep pulling in the next line of input and re-running the pattern deletion match a few times.
- Send the output to a TypeScript file so it looks pretty when opened in an IDE.
-----------------------------------------------------
Hopefully there was some useful info hidden in this wall of text. I love talking about this stuff and helping out whenever I can, so please feel free to ping me with any questions you might have. Saving someone else time is always worthwhile ![]()
-
 4
4
2 Comments
Recommended Comments